Catastrophic forgetting (CF) is a phenomenon where a model forgets previously learned information when it learns new data. This can significantly impact large language models (LLMs) during continual fine-tuning2. Knowledge Loss: CF can cause LLMs to lose previously acquired knowledge, which compromises their effectiveness. This is particularly problematic when models are fine-tuned on new tasks3. Model Scale: The severity of CF tends to increase with the model scale. Larger models (ranging from 1 billion to 7 billion parameters) are more prone to forgetting2. Comparison of Models: Some models exhibit less forgetting than others. For example, the decoder-only model BLOOMZ retains more knowledge compared to the encoder-decoder model mT02. Mitigation Strategies: Techniques like sharpness-aware minimization and general instruction tuning can help alleviate CF. These methods help flatten the loss landscape and maintain more knowledge during continual fine-tuning. Some hopeful amelioration remedies:: Elastic Weight Consolidation (EWC): This method slows down learning on certain weights based on their importance to previously learned tasks. Synaptic Intelligence (SI): This technique keeps track of the importance of each parameter and protects those crucial for past tasks. Gradient Episodic Memory (GEM): This approach involves storing a subset of examples from previous tasks and using them during new training to prevent forgetting. Low Rank Adaptation (LoRA): This method involves adapting only a small number of parameters, reducing the risk of forgetting. Sharpness-Aware Minimization (SAM): This technique flattens the loss landscape, making it easier to retain old knowledge while learning new information.
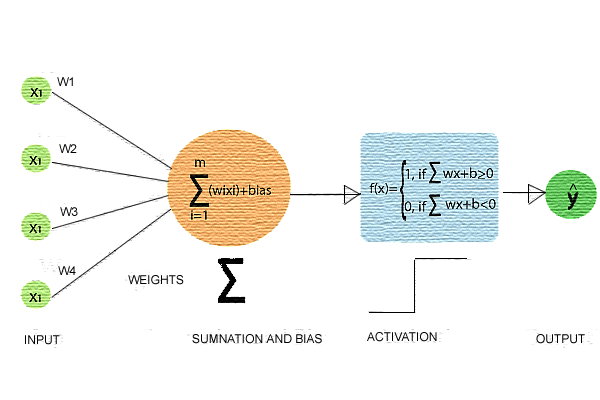
A perceptron consists of a single layer of input nodes that are fully connected to a layer of output nodes. It is particularly good at learning linearly separable patterns. It utilizes a variation of artificial neurons called Threshold Logic Units (TLU), which were first introduced by McCulloch and Walter Pitts in the 1940s. This foundational model has played a crucial role in the development of more advanced neural networks and machine learning algorithms. A weight is assigned to each input node of a perceptron, indicating the importance of that input in determining the output. The Perceptron’s output is calculated as a weighted sum of the inputs, which is then passed through an activation function to decide whether the Perceptron will fire. The weighted sum is computed as: z=w1x1+w2x2+…+wnxn=XTW Helmholtz Machine Hinton and Dayan worked on the original Helmholtz perception by inference theory, that had a double action parsing system in neural networks. A bottom to top flow (recognition mode) and an opposite top to bottom flow (generative). Using back propagation the flows were ran many times (epochs) until the desired output was produced. This has been recognised as the real start of the neural network era.
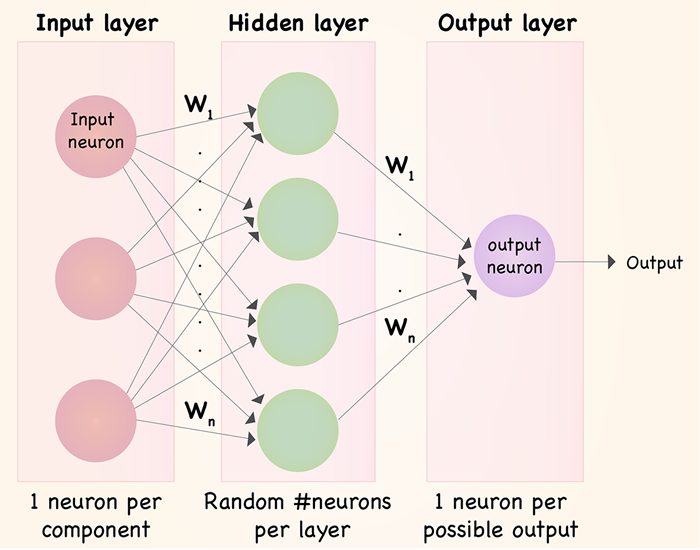
Neural networks are complex systems that mimic some features of the functioning of the human brain. It is composed of an input layer, one or more hidden layers, and an output layer made up of layers of artificial neurons that are coupled. The two stages of the basic process are called back propagation and forward propagation. INPUT LAYER: Each feature in the input layer is represented by a node on the network, which receives input data. WEIGHTS AND CONNECTIONS: The weight of each neuronal connection indicates how strong the connection is. Throughout training, these weights are changed.The weight of each neuronal connection indicates how strong the connection is. Throughout training, these weights are changed. HIDDEN LAYERS: Each hidden layer neuron processes inputs by multiplying them by weights, adding them up, and then passing them through an activation function. By doing this, non-linearity is introduced, enabling the network to recognize intricate patterns. OUTPUT: The final result is produced by repeating the process until the output layer is reached.
In 2017, researchers at Google introduced the transformer architecture, which has been used to develop large language models, like those that power ChatGPT. In natural language processing, a transformer encodes each word in a corpus of text as a token and then generates an attention map, which captures each token’s relationships with all other tokens. This attention map helps the transformer understand context when it generates new text.
The new Titans architecture addresses one of the most pressing limitations of Transformer models: their inability to handle extensive historical context efficiently. Transformers, while groundbreaking in their capability to model dependencies through attention mechanisms, function primarily as short-term memory systems, constrained by their context window size. Titans bridge this gap by introducing a neural memory module, which acts as a persistent, long-term memory, complementing the short-term focus of attention.
They combine various AI algorithms to represent and process content. For example, to generate text, various natural language processing techniques transform raw characters (e.g. letters, punctuation and words) into sentences, parts of speech, entities and actions, which are represented as vectors using multiple encoding techniques. Similarly, images are transformed into various visual elements, also expressed as vectors. One caution is that these techniques can also encode the biases, racism, deception contained in the training data. Once developers settle on a way to represent the world, they apply a particular neural network to generate new content in response to a query or prompt. Techniques such as GANs and variational autoencoders (VAEs) -- neural networks with a decoder and encoder -- are suitable for generating realistic human faces, synthetic data for AI training or even facsimiles of particular humans. Recent progress in transformers such as Google's Bidirectional Encoder Representations from Transformers (BERT), OpenAI's GPT and Google AlphaFold have also resulted in neural networks that can not only encode language, images and proteins but also generate new content.
With the end of Moore's Law, scaling AI performance at the chip level increasingly requires integrating more silicon in a single package. Many GPU and accelerator providers address this by incorporating multiple processor, memory and I/O chiplets onto an electrical silicon interposer. While this approach boosts compute capabilities within a package, the I/O bandwidth of the chip is severely constrained by the limited shoreline and the competing need to integrate more memory. Lightmatter's Passage platform overcomes these shoreline constraints by using 3D integration of customer dies directly onto a silicon photonic interconnect, enabling optical I/O anywhere across the chip area. This platform provides significantly higher connection density and bandwidth both within and outside the package. Additionally, it natively integrates Optical Circuit Switching (OCS) within the interconnect, offering enhanced resiliency and flexibility in interconnect topology. Through their partnership, Lightmatter and Amkor are delivering unmatched advantages of this combined solution to customers, enabling the industry’s largest multi-reticle die complex on an organic substrate within a 3D package.
Inside a regular neural network, the properties of each simulated neuron are defined by a static value or “weight” that affects its firing. Within a liquid neural network, the behaviour of each neuron is governed by an equation that predicts its behaviour over time, and the network solves a cascade of linked equations as the network functions. The design makes the network more efficient and more flexible, allowing it to learn even after training, unlike a conventional neural network. Liquid neural networks are also open to inspection in a way that existing models are not, because their behaviour can essentially be rewound to see how it produced an output. In 2020, the researchers showed that such a network with only 19 neurons and 253 synapses, which is remarkably small by modern standards, could control a simulated self-driving car. While a regular neural network can analyse visual data only at static intervals, the liquid network captures the way visual information changes over time very efficiently. In 2022, Liquid AI’s founders figured out a shortcut that made the mathematical labour needed for liquid neural networks feasible for practical use.